本文又名 ”是个人都会的调参“。
// 文章中用到的缩写
#define PMC "Performance Monitor Counter"
#define PMI "Performance Monitor Interrupt"
#define PGO "Profile-Guided Optimization"
#define FDO "Feedback-Directed Optimization"
#define IPO "Interprocedural Optimization"
#define LTO "Link-Time Optimization"
如化#
编译器能帮助我们进行很多优化,但有时会出现我们以为编译器已经帮我们优化了但其实没有优化,或编译器已经帮我们优化了但我们还手动优化的情况。我们不妨为该现象起一个时髦的名字——如化。以下列举两个例子。
Loop unrolling#
没什么讲的,-O3后编译器一般会自动优化。但有时编译器会过度展开,使得性能下降(i-cache, register) 。例如clang,icpx会存在这种问题。

可以针对过度展开的循环加pragma语句,手动指定展开系数#pragma unroll(n)。
Pointer aliasing#
当多个指针或引用指向同一个数据时,我们称之为pointer aliasing。
pointer aliasing会阻止编译器对一些常量的替代以及自动向量化,进而对程序的性能产生一定影响。
void foo(int a[], int b[]){
int i;
for (int i = 0; i < 100; ++i){
a[i] = b[0] + 2;
}
}
例如上述代码中,编译器假定b所指向的值可能指向a数组中的某个值,即b[0]可能发生改变,故不会将 b[0] + 2 提到循环外。
为避免此种情况,可手动将b[0]提到循环外,也可使用 __restrict__ / __restrict 关键字。即
void foo(int * __restrict__ a, int * __restrict__ p){...}
pointer aliasing 也是自动向量化的一个障碍。
for(int i=0; i<N; ++i){
A[i] = B[i] + C[i];
}
若上述代码不存在pointer aliasing时,循环可被自动向量化。但假设C=A-1 , 则循环实际上为
for(int i=0; i<N; ++i){
A[i] = B[i] + A[i-1];
}
存在循环依赖。
编译器做的优化大部分都是很保守的,即使你的程序并不存在这种依赖,但编译器只要认为存在可能,仍会阻止自动向量化等优化。同样可以用__restrict__ / __restrict 应对此种情况。
也可在for循环前加上#pragma ivdep语句,保证循环不存在循环依赖。
除了这两个情况外,还有虚函数推断、表达式化简等许多如化。那么如何应对这种令人”似郁“的情况呢?
Comparision#
以下是不同编译器所能做的一些优化的对比(取自Software optimization resources. C++ and assembly. Windows, Linux, BSD, Mac OS X)




optimization report#
编译器对代码的优化是分为不同的optimization passes进行的,每个pass都会独立的产生对应的优化信息,然后编译器对这些信息进行整合、排序的操作。
这些不同的优化信息可大致分为三类:optimized/successfully applied,missed,和notes/remarks,具体解释如下图片所示。
下面介绍不同编译器如何查看优化报告。
gcc#
-fopt-info -> -fopt-info-optimized-optall
-fopt-info-options
-fopt-info-options=filename
option大致可分为三类:描述展示哪类信息(optimized/missed/…),展示信息的详细程度(internal/high-level),包含哪些优化(inline/loop/vec/…)。
如-fopt-info-all-optall的报告如下
clang#
-Rpass-missed=.*
-Rpass=.*
-Rpass-analysis=.*
这些优化报告普遍较为臃肿,难以阅读。clang提供了一个将优化报告可视化的脚本opt-viewer.py。用clang编译时,加上-fsave-optimization-record选项,clang会为每个二进制文件生成一个.yaml格式的文件,然后可用该脚本对优化报告进行分析。

icx/icpx#
-qopt-report, Qopt-report
和clang类似,也可以用opt-viewer.py对其进行可视化分析。
Notes#
- 编译器并不会检测所有的 missed optimizations,所以一些优化没有被标为missed,并不意味其成功优化,很有可能编译器根本没对其进行优化。
- 一个小网站 https://www.godbolt.org/ 。可以在上面看看clang的可视化报告,也可以对比不同编译器对同一个代码的优化成果。
PGO/FDO#
编译器一般做的优化是静态优化,而且只对程序热点做速度方面的优化,而对其他部分做size方面的优化,以减少i-cache的压力。但它对程序runtime的信息了解很少,有时无法确定哪些代码执行的次数多,因此能做的相应优化也比较有限。
例如,以下switch语句中,如果你知道x取2的概率较大,你可以手动对其进行特殊处理,要么将其移到switch之前(v1),也可以通过加编译器directive(v2)。这种更改代码使其与数据更加匹配的方法称为data-driven optimization。
v0:
switch(x){
case 0: function_0(); break;
case 1: function_1(); break;
case 2: function_2(); break;
....
}
v1:
if (x == 2) {
function_2();
} else {
switch(x) {
case 0: function_0(); break;
case 1: function_1(); break;
....
}
}
v2:
switch(__builtin_expect(x,2)){
case 0: function_0(); break;
case 1: function_1(); break;
case 2: function_2(); break;
....
}
v2.1:
switch(__builtin_expect_with_probability(x,2,0.8)){ //case 2 独占八斗
case 0: function_0(); break;
case 1: function_1(); break;
case 2: function_2(); break;
....
}
但此种方法需要知道数据的特征,且此类优化手动实现、调整极为繁琐,这就给代码性能的维护带来了一定困难。
PGO较好的解决了此类问题。
PGO工作流程#
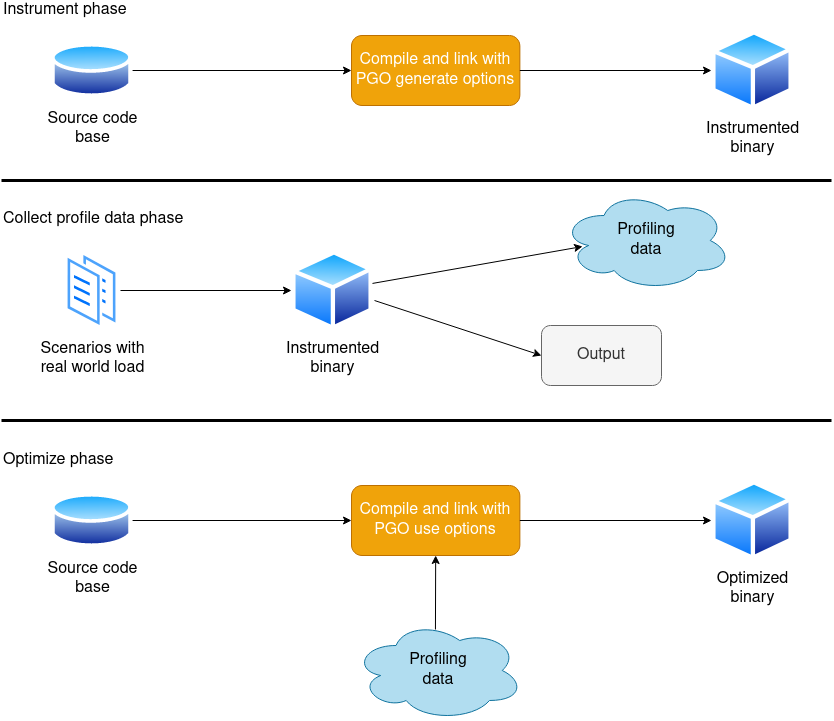
在第一阶段,通过添加特定编译器选项,生成插桩后的目标文件
在收集profile data阶段,执行程序,执行完成后会自动将收集到的profile data(如函数调用,循环,if语句等)写入一个文件。此阶段有两个方面要注意,一是在此阶段喂给程序的数据最好具有代表性。可以重复运行程序并提供不同的数据。二是profiling的overhead难以估量,实测可能会达到之前的几十倍。
最后,调整编译器选项,重新编译并运行。编译器会根据之前收集到的信息做特定优化。
Notes#
第一阶段其实有两种模式,一是instrumentation,二是sampling。
- instrumentation:算是最早的性能分析方式,将一些代码插入到程序中,以收集程序运行时的信息。最原始的插桩就是printf。现在大部分编译器支持自动插桩(主要用在PGO)。另外,instrumentation不能提供较为底层的信息(如cache miss,branch misprediction)。PAC培训课讲了关于插桩的内容。https://www.bilibili.com/video/BV1YF411y7tg/
- sampling:常用于程序热点分析。通过sampling可以知道哪些代码的哪些events耗时最高。分为user-mode和HW event-based sampling。user-mode 为程序设置一个计时器,每当计时器overflow,程序会收到一个 SIGPROF 信号。EBS 则通过维持PMC(Performance Monitor Counter),每当PMC溢出,硬件会产生一个PMI(Performance Monitor Interrupt)。程序中断后,性能分析工具会记录当前程序的状态,如当前指令的地址,寄存器状态,函数调用栈等。收集完之后,程序继续执行,直到下一次中断。
instrumentation只需添加特定的编译器选项即可。而sampling则需借助外部工具(如perf,autoFDO)。
PGO 做什么#
具体工作的取决于编译器,但以下列出了较为重要的部分。

用法#
clang#
收集:-fproflie-instr-generate
转换:llvm-profdata
再编译:-fprofile-instr-use=<filename>
clang在profiling阶段可以使用perf。但在收集前编译器选项要加-gline-tables-only. 然后再用perf收集并将收集到的信息转化成clang看得懂的(autoFDO/llvm-profgen)。最后使用profiling data时编译器选项要加上-gline-tables-only和-fprofile-sample-use。
gcc#
-fprofile-generate
-fprofile-use
gcc也可借助autoFDO分析。
icx/icpx#
不同于传统的PGO,intel引入了叫做 sample-based profile-guided optimization(SPGO),又名Hardware PGO(HWPGO)。
HWPGO通过使用hardware performance monitoring counters(PMC)收集硬件事件,使得PGO的时间开销大大降低。
- 使用
-fprofile-sample-generate编译选项,这可以确保生成有用的debug信息(这一步并不必要)。 - 使用perf收集有关分支信息。
perf record -b \
-e BR_NIST_RETIRED.NEAR_TAKEN:uppp,BR_MISP_RETIRED.ALL_BRANCHES:upp \
-c 1000003 \
-- ./your_binary
- 生成有关代码执行频率的信息。(要使用oneAPI版本的llvm-profgen,可以通过
icx --print-prog-name=llvm-profgen确定其路径)
llvm-profgen --format text \
--output=unpredictable.freq.prof \
--binary=your_binary \
--sample-period=1000003 \
--perf-event=BR_INST_RETIRED.NEAR_TAKEN:uppp \
--perfdata=your_binary.perf.data
- 生成有关分支错误预测的信息
llvm-profgen --format text \
--output=your_binary.misp.prof \
--binary=your_binary \
--sample_period=1000003 \
--perf-event=BR_MISP_RETIRED.ALL_BRANCHES:upp \
--leading-ip-only \
--perfdata=your_binary.perf.data
- 使用收集到的信息重新编译
icx -O3 \
-fprofile-sample-use=your_binary.freq.prof \
-mllvm \
-unpredictable-hints-file=your_binary.misp.prof
you_binary.c \
-o your_binary
使用建议#
PGO对含有许多频繁执行但难以预测的分支的代码优化效果最好。 该方法一般在程序优化的最后阶段进行,前期应主要关注算法和针对架构的优化等方面。
IPO(LTO)#
传统的编译、链接过程。#

LTO工作流程#
(具体细节可能因编译器而异)
编译器并不直接生成目标文件,而是先生成带有更多信息的IR,称为IL(intermediate language),并调用链接器。链接器检测到这些文件后,调用 LTO plugin 进行处理。
用法#
gcc/clang: -flto
icx/icpx: -flto/-ipo
功能#
和PGO高度相似,配合食用效果更佳。
总结#
总之,”是个人都会的调参“是一件复杂繁琐的事,选择较新版本的编译器,正确的使用pragma语句和builtin函数,清楚编译器所做的工作,并结合PGO、IPO等工具,可以为我们节省一些时间。
References#
- Software optimization resources. C++ and assembly. Windows, Linux, BSD, Mac OS X
- Performance Analysis and Tuning on Modern CPUs
- https://johnnysswlab.com/
- https://easyperf.net/
- https://github.com/hellogcc/100-gcc-tips/blob/master/src/index.md
- Excessive loop unrolling
- https://yashwantsingh.in/posts/loop-unroll/
- https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html
- https://llvm.org/docs/BranchWeightMetadata.html
- https://intel.github.io/llvm-docs/clang/UsersManual.html#profile-guided-optimization
- https://developer.android.com/games/agde/pgo-overview
- https://johnnysswlab.com/tune-your-programs-speed-with-profile-guided-optimizations/
- 鸟哥的compiler私房菜-优化学习篇
- https://documentation.suse.com/sbp/server-linux/single-html/SBP-GCC-11/index.html
- https://gcc.gnu.org/onlinedocs/gccint/LTO.html
- https://blog.llvm.org/2016/06/thinlto-scalable-and-incremental-lto.html
- https://gcc.gnu.org/onlinedocs/gcc/Developer-Options.html
- https://www.intel.com/content/www/us/en/docs/dpcpp-cpp-compiler/developer-guide-reference/2023-2/compiler-options.html
- https://clang.llvm.org/docs/UsersManual.html#options-to-emit-optimization-reports
- intel HWPGO